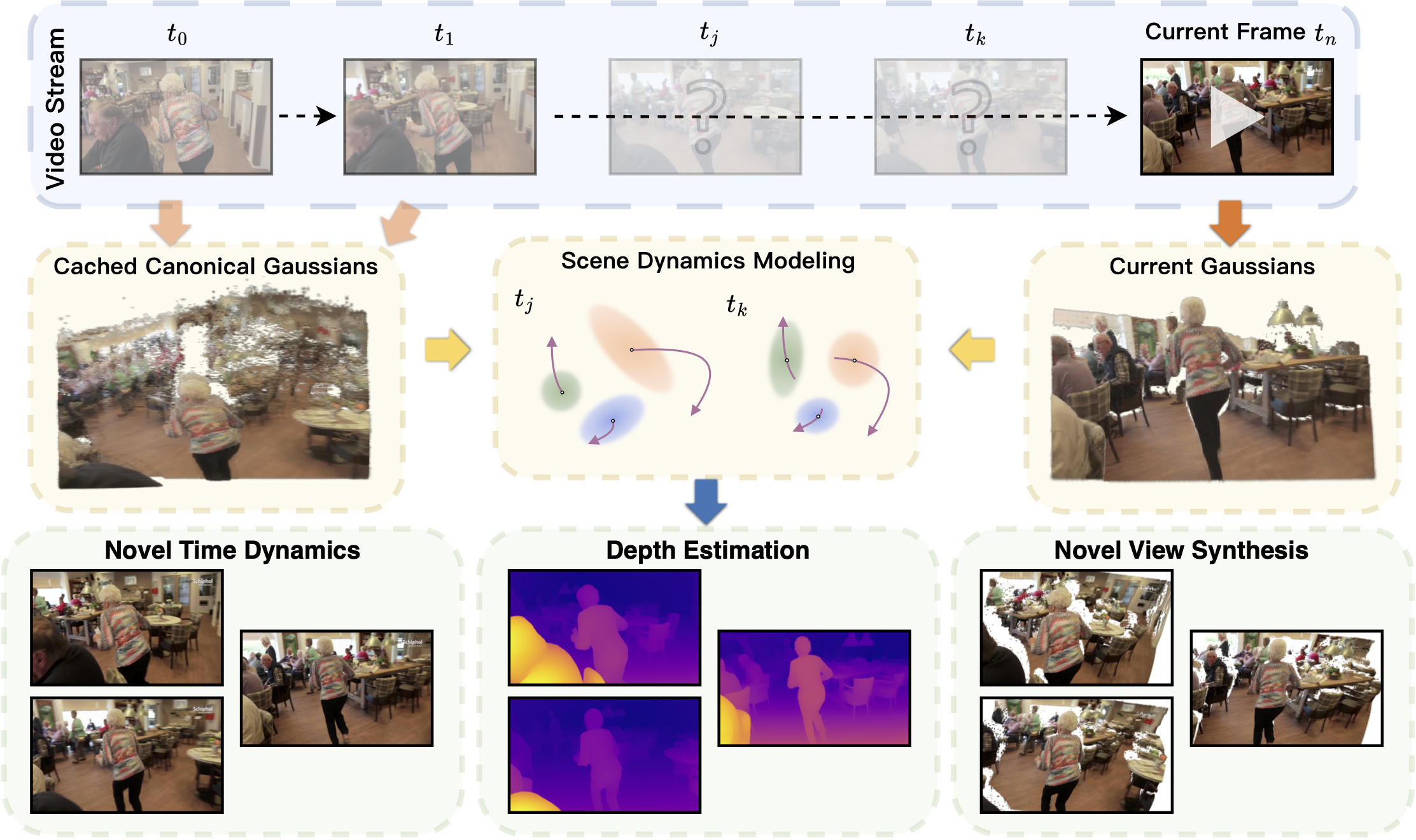
Figure 1. Given an uncalibrated video stream, StreamSplat performs instant reconstruction of dynamic 3D Gaussian scenes in an online manner, enabling video reconstruction, interpolation, depth estimation, and novel view synthesis.
Figure 1. Given an uncalibrated video stream, StreamSplat performs instant reconstruction of dynamic 3D Gaussian scenes in an online manner, enabling video reconstruction, interpolation, depth estimation, and novel view synthesis.
Real-time reconstruction of dynamic 3D scenes from uncalibrated video streams demands robust online methods that recover scene dynamics from sparse observations under strict latency and memory constraints. Yet most dynamic reconstruction methods rely on hours of per-scene optimization under full-sequence access, limiting practical deployment.
In this work, we introduce StreamSplat, a fully feed-forward framework that instantly transforms uncalibrated video streams of arbitrary length into dynamic 3D Gaussian Splatting (3DGS) representations in an online manner.
It is achieved via three key technical innovations: 1) a probabilistic sampling mechanism that robustly predicts 3D Gaussians from uncalibrated inputs; 2) a bidirectional deformation field that yields reliable associations across frames and mitigates long-term error accumulation; 3) an adaptive Gaussian fusion operation that propagates persistent Gaussians while handling emerging and vanishing ones.
Extensive experiments on standard dynamic and static benchmarks demonstrate that StreamSplat achieves state-of-the-art reconstruction quality and dynamic scene modeling. Uniquely, our method supports the online reconstruction of arbitrarily long video streams with a 1200× speedup over optimization-based methods. 🚀
No per-scene optimization. Instant 3D reconstruction in a single forward pass.
Works directly with uncalibrated monocular video — no camera poses needed.
Handles both static and dynamic elements via bidirectional deformation fields.
Processes arbitrarily long video streams with constant memory via online inference.
Qualitative comparisons of StreamSplat against competing methods, and demonstrations of 3D Gaussian point tracking.
Side-by-side comparisons on the DAVIS dynamic video benchmark against competing methods.
Side-by-side comparisons on the RealEstate10K static-scene benchmark against competing methods.
StreamSplat enables tracking individual 3D Gaussian points across frames, demonstrating temporally consistent scene-level correspondence.

Figure 2. Overview of the StreamSplat framework. Given a pair of frames, we first encode them using the Static Encoder to produce canonical 3D Gaussians, then pass the 3DGS Embeddings to the Dynamic Decoder to predict the deformation field. The resulting dynamic 3D Gaussians can be rendered at arbitrary time to produce RGB images and depth maps.
Instead of directly regressing 3D positions, we predict a truncated normal distribution for each Gaussian offset. This promotes spatial exploration during early training and stabilizes convergence, yielding a +6.36 dB PSNR improvement over deterministic prediction.
Our dynamic decoder jointly models forward and backward temporal motion between consecutive frames. Each deformation field predicts a 3D velocity and opacity coefficient, enabling smooth transitions and seamless Gaussian fusion across frames with an adaptive soft-matching mechanism.
Stage 1: Train a static encoder on RGBD inputs to produce canonical 3D Gaussians. Stage 2: Freeze the encoder and train the dynamic decoder to predict bidirectional deformation fields from consecutive frames, supervised with photometric, depth, and mask losses.




We evaluate on both static (RealEstate10K) and dynamic (DAVIS) benchmarks. StreamSplat excels especially on dynamic scenes — the core focus of our work.
| Method | Scene Rep. | Key Frames | Middle-4 Frames | Time | ||||
|---|---|---|---|---|---|---|---|---|
| PSNR↑ | SSIM↑ | LPIPS↓ | PSNR↑ | SSIM↑ | LPIPS↓ | |||
| Omnimotion | NeRF | 24.11 | 0.714 | 0.371 | – | – | – | > 8 hrs |
| RoDynRF | NeRF | 24.79 | 0.723 | 0.394 | – | – | – | > 24 hrs |
| CoDeF | NeRF | 31.49 | 0.939 | 0.088 | 19.40 | 0.498 | 0.400 | ~10 min |
| MonST3R | Points | 42.33 | 0.980 | 0.012 | – | – | – | ~30 s |
| 4DGS | 3DGS | 18.12 | 0.573 | 0.513 | – | – | – | ~40 min |
| Splatter a Video | 3DGS | 28.63 | 0.837 | 0.228 | – | – | – | ~30 min |
| DGMarbles | 3DGS | 28.38 | 0.879 | 0.172 | 21.33 | 0.619 | 0.313 | ~30 min |
| StreamSplat (Ours) | 3DGS | 37.83 | 0.982 | 0.016 | 23.66 | 0.684 | 0.193 | 1.48 s |
| Method | Type | Given Views | Novel Views | Average | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| PSNR↑ | SSIM↑ | LPIPS↓ | PSNR↑ | SSIM↑ | LPIPS↓ | PSNR↑ | SSIM↑ | LPIPS↓ | ||
| pixelSplat | Stat. | 30.70 | 0.952 | 0.055 | 28.31 | 0.905 | 0.097 | 28.99 | 0.918 | 0.085 |
| MVSplat | Stat. | 31.48 | 0.962 | 0.046 | 28.48 | 0.909 | 0.091 | 29.34 | 0.924 | 0.078 |
| NoPoSplat | Stat. | 29.50 | 0.939 | 0.069 | 28.65 | 0.913 | 0.096 | 28.90 | 0.920 | 0.089 |
| CoDeF | Dyn. | 35.13 | 0.943 | 0.091 | 20.51 | 0.591 | 0.402 | 21.77 | 0.625 | 0.374 |
| DGMarbles | Dyn. | 27.48 | 0.867 | 0.232 | 23.40 | 0.727 | 0.333 | 23.73 | 0.738 | 0.325 |
| StreamSplat (Ours) | Dyn. | 41.60 | 0.992 | 0.010 | 24.68 | 0.777 | 0.167 | 29.51 | 0.839 | 0.122 |
| Method | Type | PSNR↑ | SSIM↑ | LPIPS↓ |
|---|---|---|---|---|
| AMT | pixel | 21.09 | 0.544 | 0.254 |
| RIFE | pixel | 20.48 | 0.511 | 0.258 |
| FILM | pixel | 20.71 | 0.528 | 0.270 |
| LDMVFI | pixel | 19.98 | 0.479 | 0.276 |
| VIDIM | pixel | 19.62 | 0.470 | 0.257 |
| CoDeF | 3D | 20.34 | 0.520 | 0.365 |
| DGMarbles | 3D | 19.83 | 0.548 | 0.353 |
| StreamSplat (Ours) | 3D | 22.10 | 0.613 | 0.234 |
| Configuration | Eval. | PSNR↑ | SSIM↑ | LPIPS↓ |
|---|---|---|---|---|
| w/o Probabilistic Sampling | Key | 31.47 | 0.946 | 0.073 |
| w/o Depth Supervision | Key | 36.68 | 0.975 | 0.039 |
| Full Model (Ours) | Key | 37.83 | 0.982 | 0.016 |
| w/o Bidirectional Deformation | Mid. | 18.89 | 0.582 | 0.492 |
| Full Model (Ours) | Mid. | 23.66 | 0.684 | 0.193 |
Exploring real-time dynamic reconstruction for autonomous navigation scenarios.
Leveraging dynamic 3D representations for controllable video synthesis.
Adaptive mechanisms for fusing Gaussians across longer frame histories.
@article{wu2025streamsplat,
title={StreamSplat: Towards Online Dynamic 3D Reconstruction from Uncalibrated Video Streams},
author={Wu, Zike and Yan, Qi and Yi, Xuanyu and Wang, Lele and Liao, Renjie},
journal={arXiv preprint arXiv:2506.08862},
year={2025}
}This work was funded by the NSERC DG Grant, the Vector Institute for AI, Canada CIFAR AI Chair, and a Google Gift Fund. Resources provided by the Province of Ontario, the Digital Research Alliance of Canada, and Advanced Research Computing at UBC.
This project builds upon 3D Gaussian Splatting, DINOv2, Depth Anything V2, Gamba, NutWorld, and EDM.